AWS Cost Controls
I recently did 2 meetup presentations about FinOps and AWS cost optimization. Inspired by the talks, I thought it would be a good idea to write a shopping list of things to cover in order to keep AWS costs in control. While this is written especially for AWS, the same ideas apply to Azure and GCP as well.

Visibility
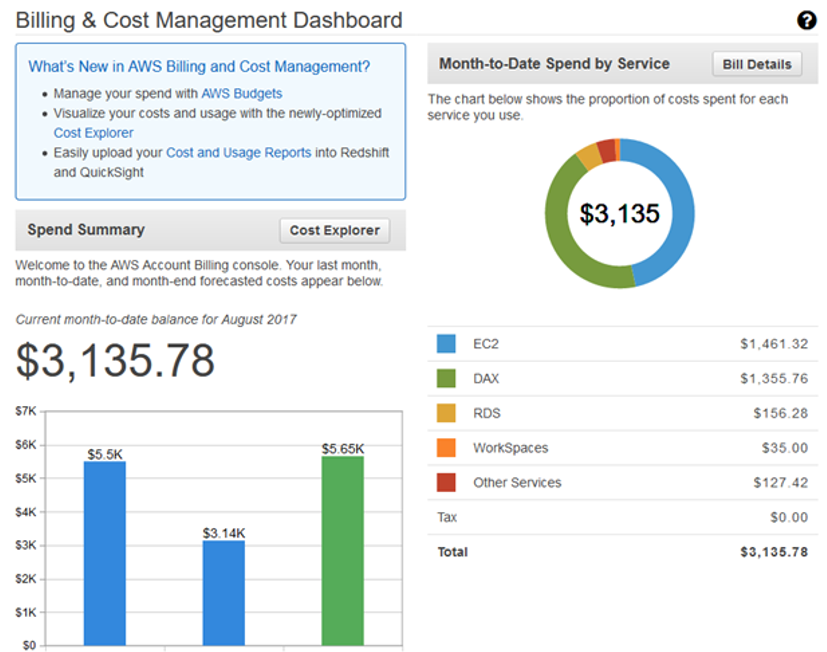
Everything starts from making things visible. If you don’t know how much (and why) running your service costs, it is going to be very difficult to improve it either. AWS Cost Explorer is good starting point and complementing it with AWS Budgets, Billing Alerts, Cost and Usage reports and AWS Cost Categories will get you already pretty far. While these services are not completely free, cost is based on usage, not % of your AWS bill like most 3rd party services do.
Resource tagging is the basis for detailed cost allocation. However it is almost impossible to keep all the resources 100% correctly tagged and some resources can’t be tagged at all. Ultimate solution for cost allocation is divide resources into multiple accounts so each account has single team/organization responsible of it’s cost. Tags are still important when analyzing the costs and shouldn’t be overlooked even if costs are allocated per account.
Second dimension of visibility is sharing results and best practices between teams. At best cases this will create friendly competition and motivate people to do their best, or in worst case cause blame-games when people just look at raw numbers and don’t understand different nature and requirements of services/teams.
Waste Management
Waste is resources not used or seriously over provisioned to their real use. Typical examples include
- Unattached (or overprovisioned) EBS volumes
- Aged snapshots
- Unassociated IP addresses
- Idle load balances (with no backends)
- Underutilized EC2/RDS instances
Instead of just focusing on managing/deleting these resources, try to find the root cause for wasteful usage and orphan resources. Often the solution is adding more automation when building stuff as by definition orphan resources are either created manually or incomplete automation.
Typical example how one can create a lot of unintended orphan EBS volumes is forgetting to set DeleteOnTermination -flag when creating an AMI and using it with auto scaling group actively adding and deleting instances. This can create 100’s orphan volumes before someone starts asking why EC2 costs are raising.
Another example of collecting is waste is running a script or lambda function that takes snapshots of all EBS volumes on daily/hourly basis. While this works as backup solution, defining lifecycle of snapshots isn’t always included in the process and old snapshots are starting to pile up. Better solution would be using AWS Backup and setting up a backup plan including lifecycle policy for snapshots. This will not only help in waste management but can be essential for data privacy and security compliancy.
Scheduling

Running EC2s only when you need them can be very effective. If instances are only being used during the office hours (and little bit safety margin on top that) it can reduce the running cost to almost 1/3 of original (12h/day * 5 days vs 24h/day * 7 days).
To stop paying you don’t have to stop the instance, but just hibernate it. It can thenb be woken up as quickly as your laptop wakes then the lid is opened. Hibernation and waking up can be triggered by schedule and/or external events like click of an IoT button.
Right Sizing
Right sizing contains the idea of knowing the current usage. For some things this is easy as there are Cloudwatch metrics telling how much CPU or network bandwidth is being used. Most important parameter that is not available in Cloudwatch by default is EC2 memory utilization.
EC2 instances can have very low CPU utilization but before you can be sure if those can be down-sized to smaller instance type, you must verify if it has enough memory (+ network and ebs bandwidth) to keep service running.
While tuning instance types, consider upgrading to the latest instance generation, e.g. from C3 to C5. New Nitro -architecture instances have a bit lower price and more CPU performance, that might allow to switch smaller instance type for non-memory bound workloads. But as always read the small print first and check if your current OS is compatible and there aren’t any features (instance storage) missing from the new instance generation.
Reservations
Reserved Instances are propably the most wellknown AWS cost optiomization tool. Tha Basic idea is to make a commitments for next 12 or 36 month for certain amount of EC2 capacity and in exchange get discounted hourly rate. There are many different flavors of reservations including full, partial or no upfront payments and fixed or convertible instance types.
Don’t forget reservations are also available for
- RDS
- Redshift
- ElastiCache
- DynamoDB
- CloudFront (>10TB/month)
Spot Instances
No AWS cost optimization post wouldn’t be complete without EC2 Spot Instances. If ‘spot’ makes you think of complex pricing strategies, it hasn’t been so for awhile. Today it is rather simple to run stateless autoscaling services on combination of reserved and spot instances enjoying the best of both models.
Spot instances are no longer only for workloads that can be terminated at will. It is also possible to stop or hibernate instances, and continue later when spot capacity is available.
Savings Plans
The Idea of Savings Plans is similar to Reservations, except it is even more flexible. You just commit to certain hourly spend either on EC2 instances or AWS Computing including EC2, Fargate and Lambda. Please note the commitment is made on hourly spend, i.e. steady spend 24/7, not average hourly spend over a month.
At First it may sound that Savings Plans make reservations obsole, but keep in mind that it doesn’t (yet?) cover other than EC2, Fargate and Lambda. And most importantly both RIs and Savings Plans apply to EC2 consumption. But unfortunately not at the same time. RIs are applied first and then savings plans to remaining On Demand usage.
Serverless Refactoring
Switching from server based (pay-per-provisioned) to serverless (pay-per-use) architecture can change the whole cost structure. This is especially true, when there is no small enough resources available and it is not possible to avoid over-provisioning. If uncertainty of paying for every execution sounds scary, think what you could do alone with Lambda free tier; 128MB function, running 0.25s at the time, can be run 12.500.000 times in a month before reaching the limit of Lambda free-tier.
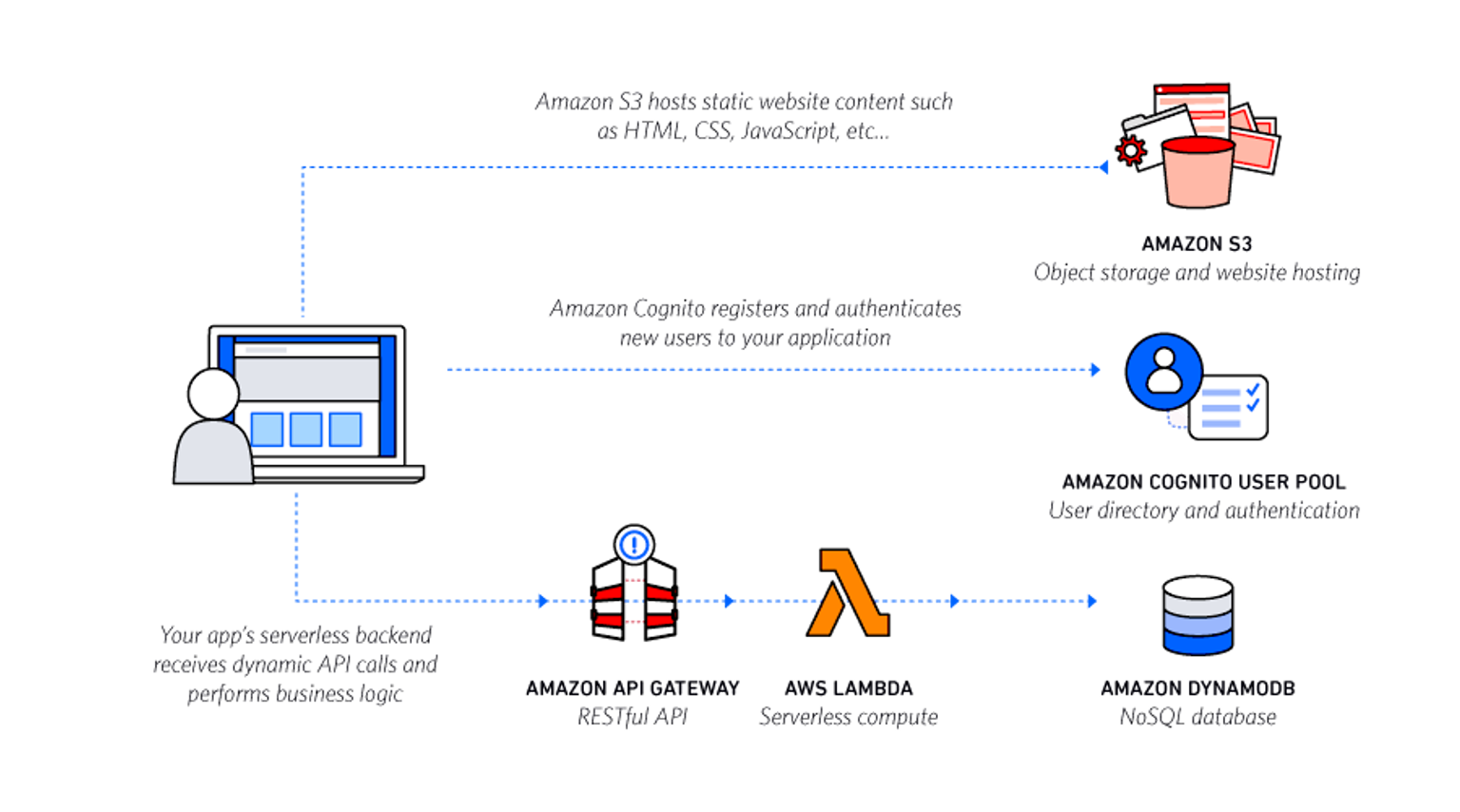
Refactoring effort can be hard to justify with savings in running costs alone. There are also other benefits in building on serverless (=no servers to manage) architecture; no servers to scale, patch, backup etc. Or think it as technical debt payback in general.
Summary
A Typical strategy of implementing cost optimizations is to start from low-complexity (and high impact) items. Implement savings plans & reservations, and do a bit of waste management. Then work towards scheduling, spots & right-sizing, and maybe one day think about serverless architecting the whole thing.
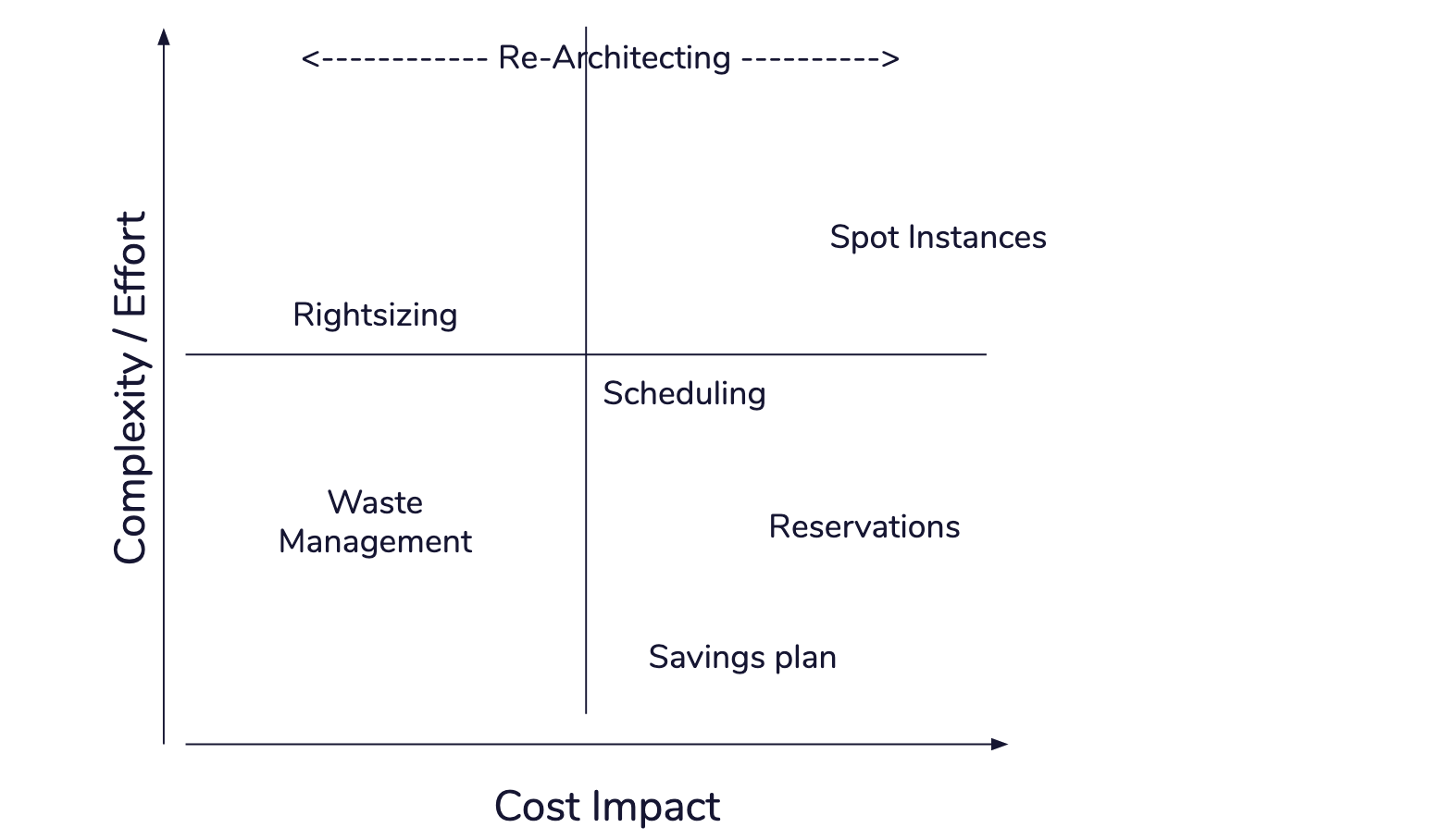
While it makes perfect sense to get cost optimizations implemented ASAP and stop paying for more than you must, it is not recommended to do all commitments to maximum at once, before seriously exploring possibilities of harder items as right-sizing, spots and refactoring the architecture of (some) services. All those affect commitments that can be made on onsumption in both total volume and types of services being used.
Cost optimization is a process, not project.