Closer look at AWS data transfer cost
Please raise your hand (virtually) if you think AWS data transfer cost is difficult to allocate for applications or resources generating it, because data transfer can not be tagged. I was part of that group too, until recently. If that got you interested, here is another post in series of an old dog learning (not so) new tricks …
You can not tag a network packet
The Foundation of AWS cost allocation are the cost allocation tags. But it is not possible to tag network packets and this is what lead to common mis-believe it wouldn’t be possible to allocate the data transfer costs on more granular level than per account.
But if you have tagged, or are able to pick the resources that generate the traffic some other way in Cost Explorer, you can actually see how much traffic they generate, both in $’s and GBs. As seeing is believing, here is how you do that.
Mapping data transfer in Cost Explorer
First step is to filter EC2: Data Transfer Usage Type Groups. There are 6 different
groups of data transfer. For a demo I have selected them all. You might want to leave Cloudfront
out depending your use-case, as that be reflecting the tags you have set for distribution and not
the originating resources in your VPC.
Adding key-value -pairs for tags of resources you are interested in, will show you data traffic
on daily (or hourly) level. For the demo I did choose all value of env -tag
but you could as well just filter for an application or specific resource(s).
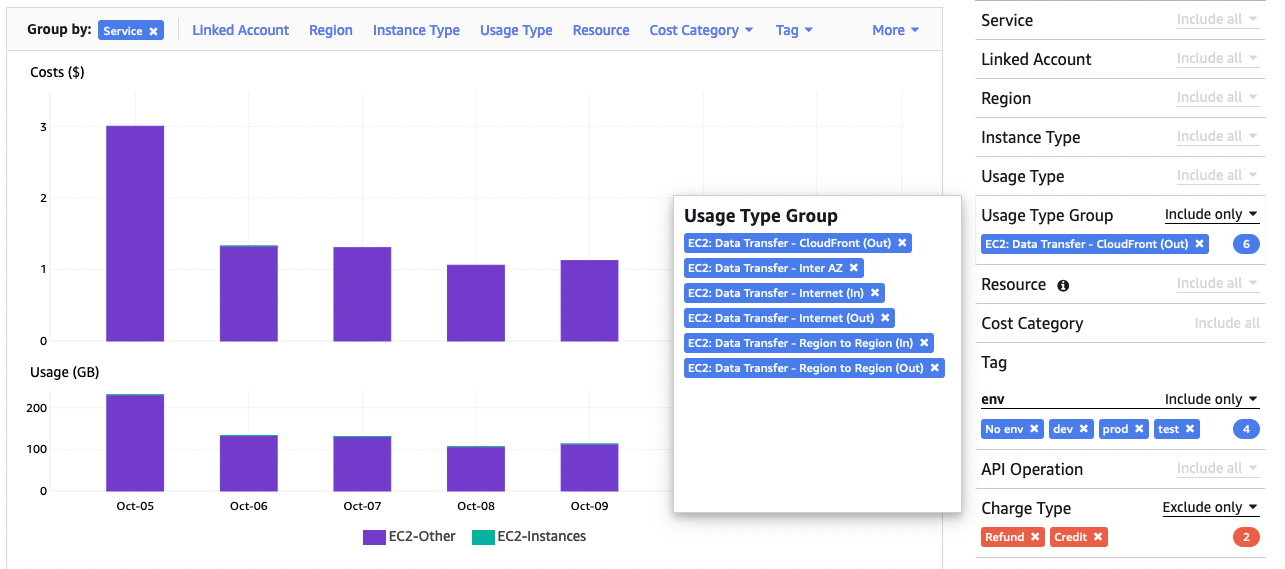
Then you can view how the usage is split for different environments using “Group by” env -tag.
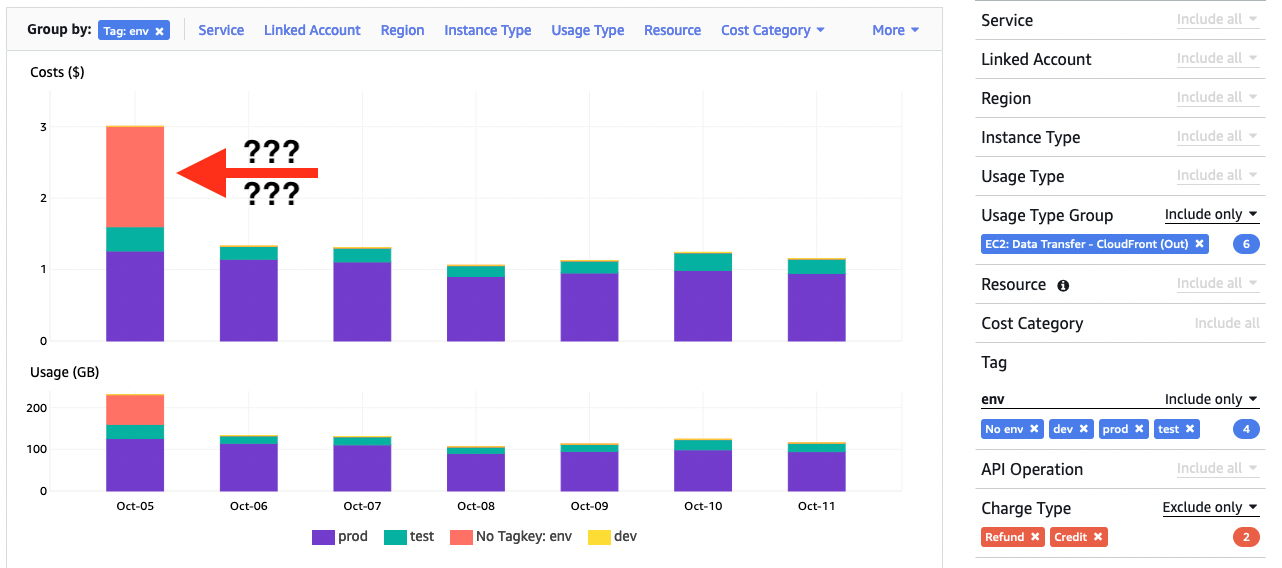
I was expecting to see data transfers nicely allocated for different values of env but
about half of Oct 5th costs is not tagged ?!? To investigate further I did another “Group by” with
“Usage Type” that will show e.g. cross-region traffic. Untagged data transfer seems to be originating
from something being moved from eu-central-1 to eu-north-1 …
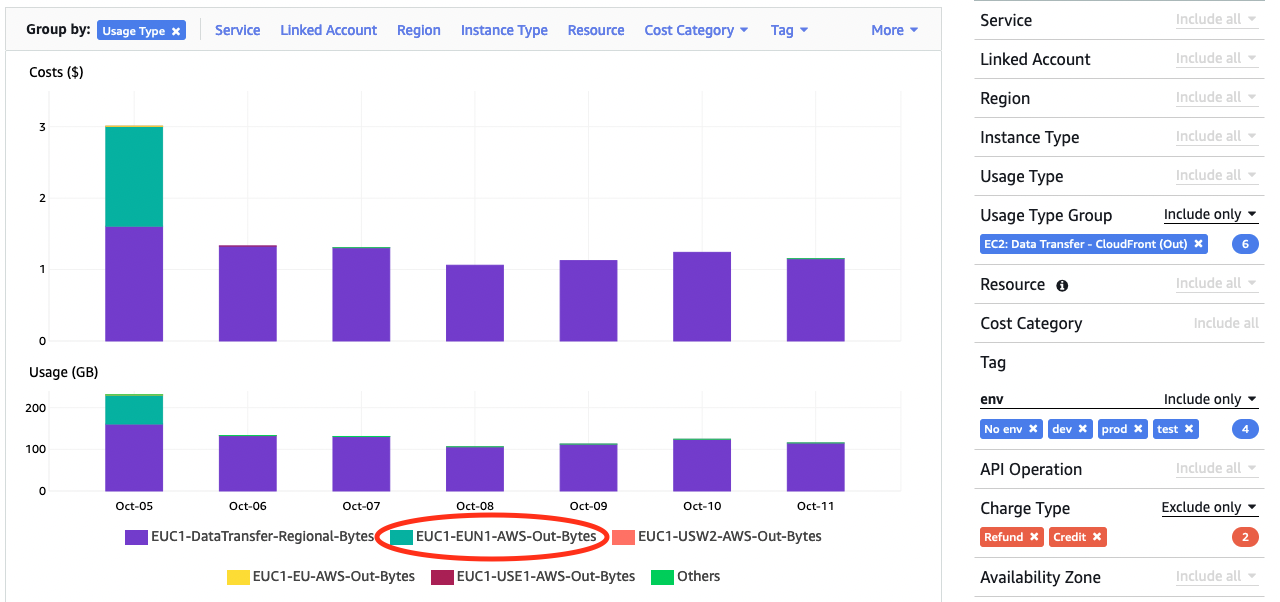
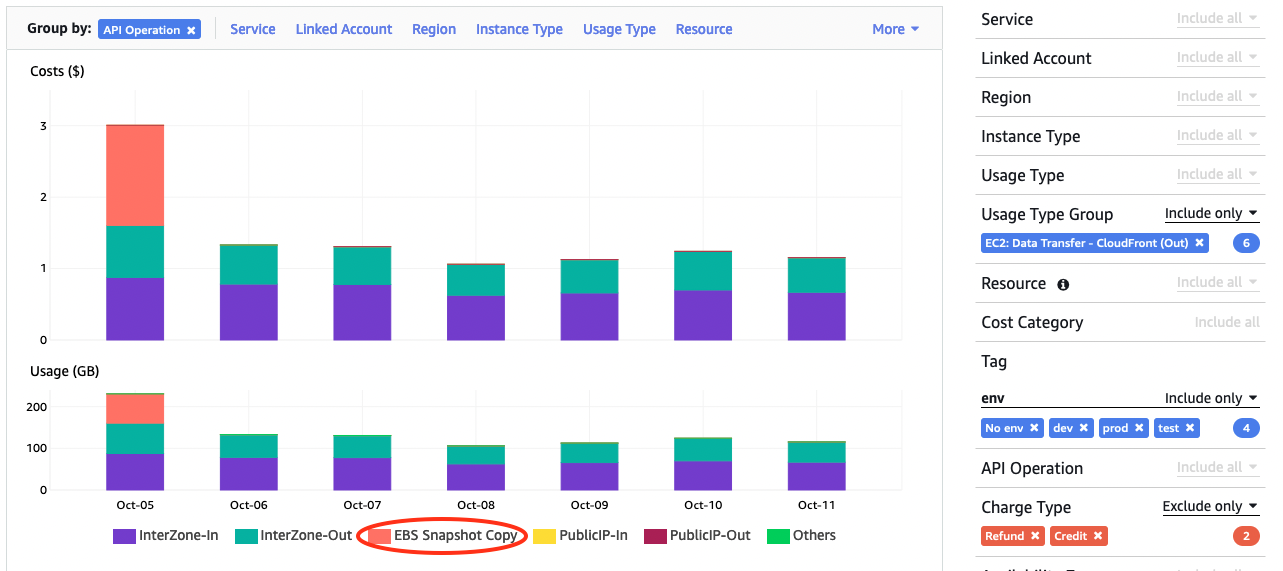
Knowing that eu-north-1 is the backup region for services running at eu-central-1 this gives me a hint to do a one more grouping with “API Operations” revealing untagged data transfer is because of snapshots copied between regions. Mystery solved, but also a reminder that not all data transfer can not be tagged, especially when originated indirectly from a use of AWS services.
Optimising data transfer
Now that you know how much data transfer cost is, and from where is it coming from, what can you do about it?
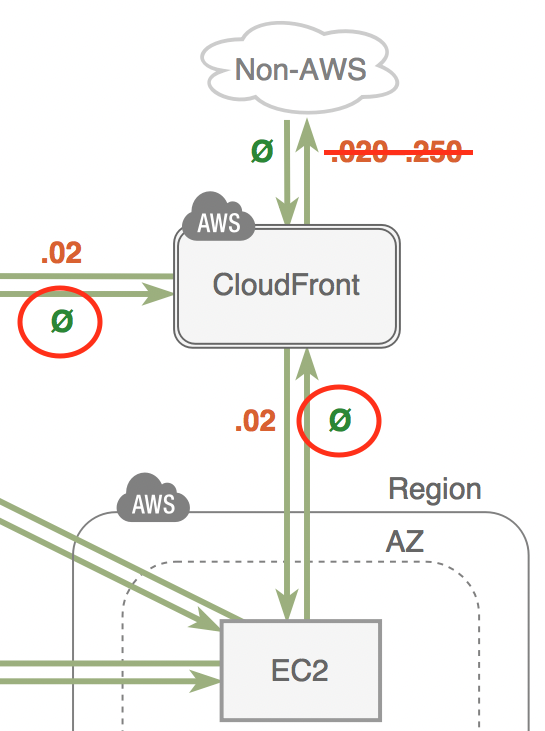
First thing is to understand how and where the cost occurs. From EC2 pricing you can find the raw numbers, and learn e.g. first 100GB of data out to internet is free and then you start paying $0.09 per GB. However to get an overview what is free and what is not, I would recommend a diagram from Open Guide to Amazon Web Services or Last Week in AWS. Numbers on those can quickly get out-of-date, but free vs billed should be accurate.
Next thing is to remember there is also 1TB per month free data transfer to internet when you go through Cloudfront, and data transfer from your services to Cloudfront is free. This should cover the data transfer for a serious pet project or maybe even a small scale global business :-)
Third easy fix would be avoiding unnecessary cross-AZ traffic when architecting for HA. Keeping the traffic flow within the single AZ in multi-layer architecture would not only reduce the cost and latency, but also make your service more resilient for AZ failures.
Summary
Against a common(?) belief, it is possible to allocate data transfer costs to applications, environments and resources, within an AWS account. This is important to motivate and monitor any optimization efforts, and can sometimes also lead in finding sub-optimal designs when traffic is routed across AZ boundry for no good reason.
Edit 19/10/2022; Here is another good summary of data transfer costs for both server and serverless architectures.