Multi-region filesystem for disaster recovery
 Building Legos and services in AWS have a lot in common. Both started from handful of different
bricks you could join in many ways to build almost anything. And then evolved to over 200 different
services and almost 4000 bricks.
Building Legos and services in AWS have a lot in common. Both started from handful of different
bricks you could join in many ways to build almost anything. And then evolved to over 200 different
services and almost 4000 bricks.
In this post I’m going to build a managed multi-region filesystem service from common household services available to anyone. You could use this for disaster recovery or expanding your service to multiple-regions, within certain constraints. But lets define first what disaster recovery is …
Definition of disaster recovery capability
Service has a disaster recovery capability in AWS when there is
-
a documented and tested process
-
to deploy infrastructure and restore data
-
into another account and region
-
creating a discrete copy of the service.
1st statement is kind of obvious. If there is no documentation, or testing, it is hard to say if something is working or not. 2nd statement is about ability to rebuild the stateless part (infrastructure) and restore the state (data). Usually the challenge is in data backup and restoration. Using IaC takes care of infrastructure rebuild.
3rd and 4th statements are what make this disaster recovery. Deploying into different account and region protect agains natural disasters and most importantly bad actors getting access to your primary environment. And when recovery is completed you should have new discreate copy of the service that has no dependency to the original, compromised, instance of the service.
Now Go Build
Let’s start collecting the building block. As this is going to be a managed filesystem I have 2 (or actually 5) options to choose from.
-
Amazon Elastic File System (Amazon EFS) is a simple, serverless, set-and-forget, elastic file system. It provides shared access to data using a traditional file sharing permissions model and hierarchical directory structure via the NFSv4 protocol.
-
Amazon FSx makes it easy and cost effective to launch, run, and scale feature-rich, high-performance file systems in the cloud. You can choose between four widely-used file systems: Lustre, NetApp ONTAP, OpenZFS, and Windows File Server.
EFS is regional service that can have read replica in another region but within the same account. While read replica can help in disaster recovery it doesn’t meet the multi-account requirement and replication lag can be upto 15 minutes. AWS DataSync could transfer files between two EFS filesystems, including filesystems in different AWS Regions and owned by different AWS accounts, but this feels bit hacky solution, including EC2 instances running the sync processes. So I’m going to skip EFS for now.
At first glance above is also true for all flavours of FSx. I also left S3 Mountpoint off from the list as it doesn’t implement fully featured filesystem but is at its best when you need filesystem interface to read data from S3.
While S3 bucket namaspace is global, buckets (and data in them) are stored into specific region. Fortunately object replication can be configured to sync data bi-directionally between buckets in different regions and/or accounts, that was a requirement for the project. Unfortunately S3 isn’t fit for general purpose filesystem as I just noted above :-(
If only there was a way to join one of the above managed filesystem services with S3.
But there is …
Putting Bricks Together
At reInvent 2021 there was an announcement, that might have gone unnoticed, of improved AWS FSx Lustre performance. In the very end there was also this short note about S3 integration.
… you can also link the next generation file systems to Amazon S3 buckets, allowing you to access and process data concurrently from both a high-performance file system and from the S3 API.
Sébastien Stormacq did much better in his blog explaining new features of S3 integration.
First, a full bi-directional synchronization of your file systems with Amazon Simple Storage Service (Amazon S3), including deleted files and objects. Second, the ability to synchronize your file systems with multiple S3 buckets or prefixes.
This would make it possible to keep 2 Lustre filesystems in sync via S3 replication!
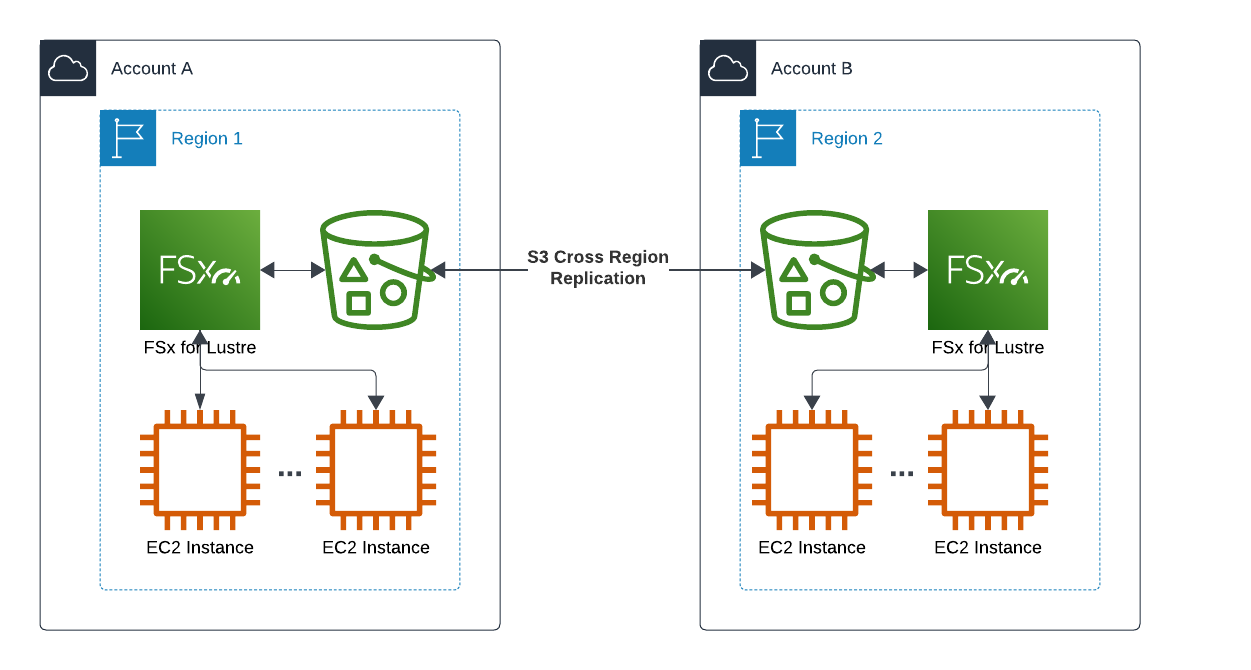
1. Setup S3 Buckets with Cross-region Replication
First step is to create 2 buckets into different accounts & regions, and configure replication between them. This is something you can find prior art, example aws-bidirectional-crossregion-replication Github repo has it packaged into nice Cloudformation templates.
NOTE1: Above Github repo doesn’t enable versioning. This is OK for POC but for disaster recovery purposes it is essential to enable versioning to be able to undo any unwanted changes. Versioning must be enabled on both source and destination buckets before replication is enabled.
NOTE2: S3 replication will keep 2 buckets in-sync, for any changes after the replication was setup. This won’t sync any objects created before replication was enabled. If you need to do this initial sync, consider S3 Batch replication before enabling object replication.
2. Creating FSx Lustre Filesystem
Once S3 buckets have been configured, you need to create FSx Lustre filesystems to the same regions as the S3 buckets are. Minimal configuration of persistent HDD based filesystem of 1.2TB capacity and 12MB/s/TB throughput should be perfect for testing purposes. Don’t forget to link filesystem with S3 bucket in Data Repository Import/Export -settings.
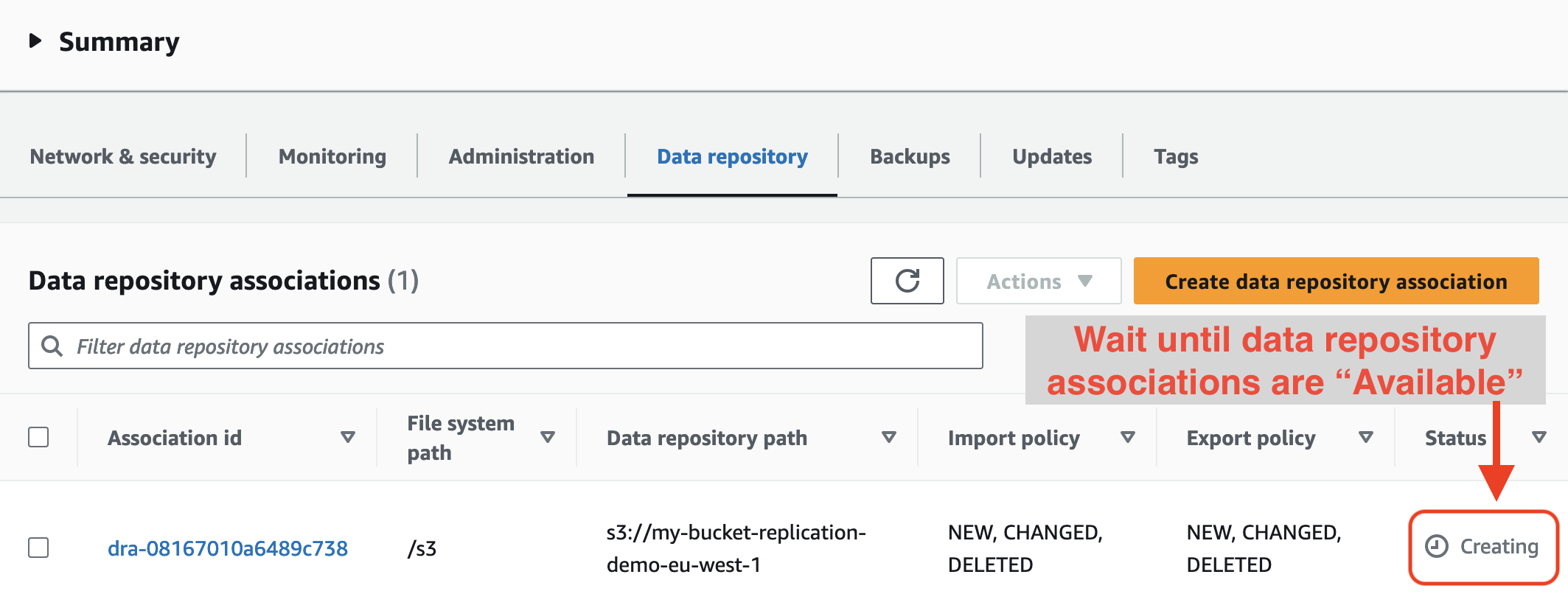
When the filesystem is available, remember to wait until Data repository associations are also available. Filesystem can be mounted immediately when it becomes available, but you won’t see data in S3 until association is available.
3. Mounting Lustre Filesystem
Next step is to install Lustre client on your Linux instances. Many modern distributions have the client available with exception of Amazon Linux 2023.
$ uname -r
5.10.196-185.743.amzn2.x86_64
$ sudo amazon-linux-extras install -y lustre
Installing lustre-client
Loaded plugins: extras_suggestions, langpacks, priorities, update-motd
Cleaning repos: amzn2-core amzn2extra-docker amzn2extra-kernel-5.10 amzn2extra-lustre
...
And then mount the filesystem with instructions from AWS console.
$ sudo mkdir /fsx
$ sudo mount -t lustre -o noatime,flock fs-deadbeef12345678.fsx.eu-central-1.amazonaws.com@tcp:/tesmrbmv /fsx
$ df -h /fsx
Filesystem Size Used Avail Use% Mounted on
10.0.0.128@tcp:/tesmrbmv 1.2T 7.5M 1.2T 1% /fsx
4. Testing Cross Region Replication
For testing purposes I created a file to filesystem at eu-central-1 and recored the timestamp.
[eu-central-1]# echo "Hello World" > /fsx/s3/hello.txt; date
Sun Oct 22 17:16:41 UTC 2023
And then waited in a loop for the file to appear to filesystem at eu-west-1.
[eu-west-1]# while true; do cat /fsx/s3/hello.txt 2> /dev/null || date; sleep 1; done
Sun Oct 22 17:16:45 UTC 2023
Sun Oct 22 17:16:46 UTC 2023
NOTE: S3 object timestamp October 22, 2023, 17:16:46 (UTC)
...
Sun Oct 22 17:17:08 UTC 2023
Sun Oct 22 17:17:09 UTC 2023
Hello World
In this non-scientific test replication from one filesystem to another took 28 seconds. Not exactly a real time but very decent result. Most of the time was spend in S3 replication (and second filesystem picking up changes). The File itself was synced to S3 within 5 seconds.
NOTE: Propagation of changes to remote region depends on S3 replication speed. S3 Replication Time Control provides visibility replication performance. S3 SLA promises 99.99% of changes to be replicated within 15 minutes.
Considerations
With combination of FSx Lustre filesystem and S3 replication & versioning, it is possible to create a managed filesystem that meets disaster recovery needs and also can help you running legacy applications at multiple regions by providing a shared filesystem storage.
FSx Lustre is build mainly for HPC use-cases, but bi-directional sync with S3 allows you also to build integration with ETL workflows when some of the tools use S3 objects and others prefer filesystem interface. However if you don’t need full bi-directional functionality, mountpoint for S3 might be less expensive solution.
Price range for FSx Luster is wide. Starting from $0.025 per GB-month for HDD based 12 MB/s/TB throughput to $0.600 per GB-month for SSD based 1000MB/s/TB throughput. For smallest 1.2TB deployment above price range would be from $60/month to $1440/month for 2 FSx Lustre filesystems.
In this demo I created Lustre filesystem on both regions. This is not a strict requirement if you are only building disaster recovery capability. It is enough to get the data to S3 and replicated to another bucket on different account & region. Second Lustre filesystem can be created during recovery process. This is would cut 50% of the FSx cost.
You can share single Lustre filesystem with multiple client applications, and mount only the subtree of filesystem that given application needs. However there is no permission model to prevent clients mounting other parts, or whole filesystem. Sharing Lustre filesystem is possible but only when you can trust all clients.
FSx Lustre filesystem is single-AZ resource with similar SLA to EBS volume, but the data stored into S3 is highly durable. If you require multi-AZ deployment, you could consider FSx Netapp ONTAP. While the blog post is talking only about multi-region setup, it would make sense that Netapps could be deployed into separate accounts joined together via TGW or VPC peering. Netapp replica is read-only, the same way as EFS replication does.