S3 Data Loss Prevention with Encryption
S3 server-side encryption can help you to tick the checkbox “☑ Yes, I have encrypted my data at rest” but it can also help in solving real-life challenges and prevent data leaks. Write-only S3 bucket is one such pattern you can implement with encryption, key management and multiple AWS accounts.
I have 3 AWS accounts, each with different role.
-
Security -account (111111111111) is for hosting all KMS keys. It is important to use Customer Master Keys (CMK) because it is not possible to attach policies for AWS managed default keys. Enabling the server-side encryption with default keys is really easy but it only helps to tick that checkbox and not much more than that.
-
Data intake -account (222222222222) is where data is written (and encrypted) to S3 bucket. Important feature here is that once you write something to bucket, there is no way you can read it from the same account. Not even with root permissions. This doesn’t require changes to application as encryption is done on (S3) server-side. I’m using AWS Transfer as a sample of intake application.
-
Data processing -account is where you want to read data from S3. Once again decryption is done transparently from application point-of-view. All that is needed is permission to use KMS key from security -account.
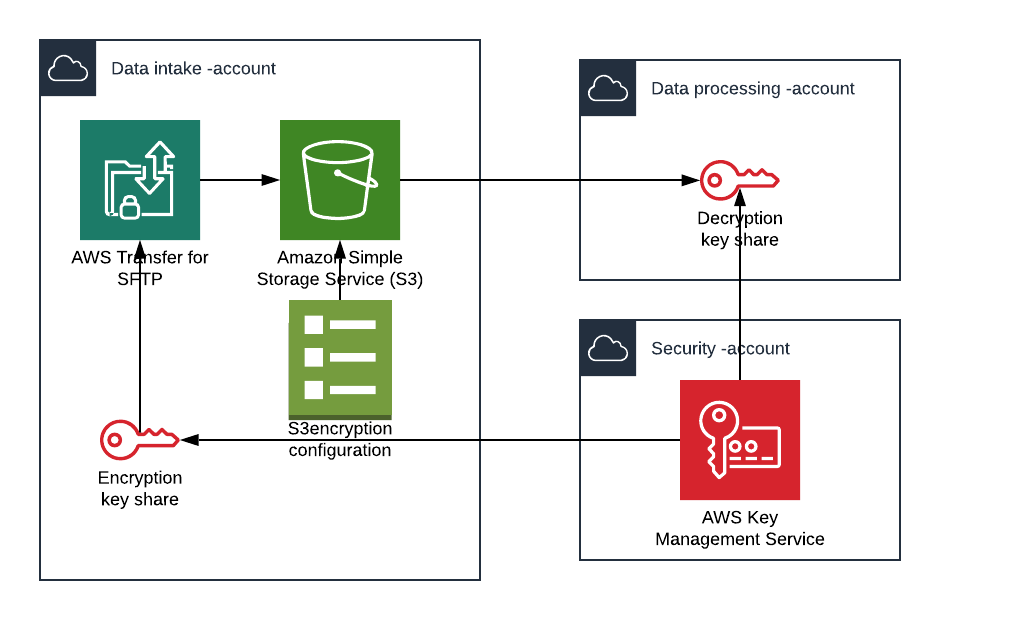
First I create CMK on security -account and attach a key policy that allows intake -account (222222222222) to use key for encrypting (but not for decrypting). Policy below will also allow AWS services on intake -account to use this key, ie. AWS Transfer can use it for encrypting objects put into bucket.
{
"Sid": "Allow Encryption with the key",
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::222222222222:root"
},
"Action": [
"kms:Encrypt",
"kms:ReEncrypt*",
"kms:GenerateDataKey*",
"kms:DescribeKey"
],
"Resource": "*"
},
{
"Sid": "Allow attachment of persistent resources",
"Effect": "Allow",
"Principal": {
"AWS": [
"arn:aws:iam::222222222222:root"
]
},
"Action": [
"kms:CreateGrant",
"kms:ListGrants",
"kms:RevokeGrant"
],
"Resource": "*",
"Condition": {
"Bool": {
"kms:GrantIsForAWSResource": "true"
}
}
}
On data processing account I create a similar policy statement for decryption with the same key.
For S3 bucket on intake -account I enable S3 server-side encryption using remote CMK.
{
"ServerSideEncryptionConfiguration": {
"Rules": [
{
"ApplyServerSideEncryptionByDefault": {
"KMSMasterKeyID": "arn:aws:kms:eu-west-1:111111111111:key/abcd1234-acdc-1234-5678-deadbeef",
"SSEAlgorithm": "aws:kms"
}
}
]
}
}
Next I create IAM policy and role to allow AWS Transfer to upload and encrypt objects into my S3 bucket. Sample IAM polices are shown in AWS documentation but I must also include permission to use the KMS key defined in S3 encryption configuration.
{
"Sid": "KMSaccess",
"Effect": "Allow",
"Action": [
"kms:Encrypt",
"kms:ReEncrypt*",
"kms:GenerateDataKey*",
"kms:DescribeKey"
],
"Resource": "arn:aws:kms:eu-west-1:111111111111:key/abcd1234-acdc-1234-5678-deadbeef"
}
Now all objects uploaded to bucket by Transfer (or any other method) are transparently encrypted with the key that is hosted on another account. Even the root user on intake -account can’t read data after it is uploaded. Control over the readers and writers is on security -account.
And because all encryption/decryption is done on server side, the same effect applies no matter how I access the bucket. I can write and read object metadata from the bucket with AWS CLI but reading the object I just uploaded, will result an error.
$ aws s3 cp hello.txt s3://my-write-only-bucket/
upload: ./hello.txt to s3://my-write-only-bucket/hello.txt
$ aws s3 ls s3://my-write-only-bucket/hello.txt
2019-11-03 14:43:53 7 hello.txt
$ aws s3 cp s3://my-write-only-bucket/hello.txt world.txt
download failed: s3://my-write-only-bucket/hello.txt to ./world.txt
An error occurred (AccessDenied) when calling the GetObject operation: Access Denied
Encrypting objects will keep data safe, even in case of mis-configuration that would make bucket public. Without access to KMS key, objects can not be read. Having S3 and KMS configurations on separate accounts reduces the likelyhood of both configuration errors happening at the same time by mistake or on purpose.