Thinking outside of the VPC
(or warm standby architecture with IP failover in the Cloud)
Background and the Problem
As long as you have stateless servers that can run in active-active -configuration (that’s kind of build into stateless-nes) it is trivial to build highly available architectures by placing a load balancer in front of the servers. However when migrating legacy services to public cloud, it is not uncommon to run into software architectures that just don’t work with load balancing.
Typical problem is statefull server running a service that can be active only on single instance at the time with clients using an IP address to connect (not DNS name) because DNS caching would make failover too slow or unreliable. So you would need a static IP that could failover to active server.
IP failover may not sound too difficult at first, attach an elastic network interface (ENI) to your instance and if the server stops responding, detach and re-attach it to next instance with some Lambda -magic 🦄. But what if instances are in different AZs?
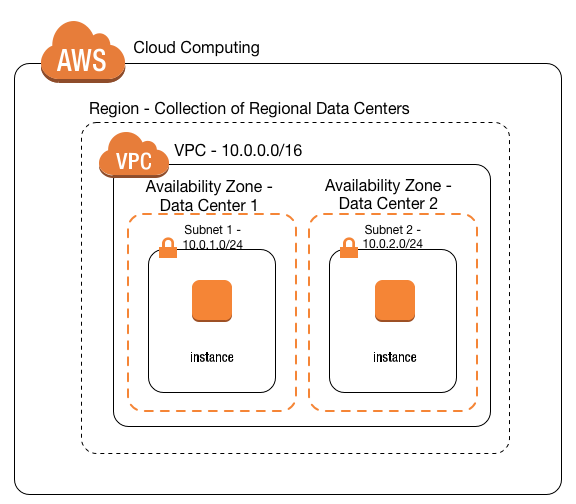
Amazon VPC for On-Premises Network Engineers
Best practice for highly available service is to have servers in multiple AZs, but ENI (and subnet) are AZ specific. As servers would be in different subnets, it is not possible to have the same private IP assigned to both of them, right? (don’t even start thinking about using public elastic IP and exposing servers to internet just because of IP failover)
Solution
Fortunately there is an easy way to setup IP failover between availabity zones.
- Assign virtual IP to both instances interfaces. Actual command might vary a bit depending on your OS/distribution but on Ubuntu 18 below cmd will add 10.10.10.10 as secondary IP for eth0 interface.
# ip addr add 10.10.10.10/32 dev eth0 label eth0:1
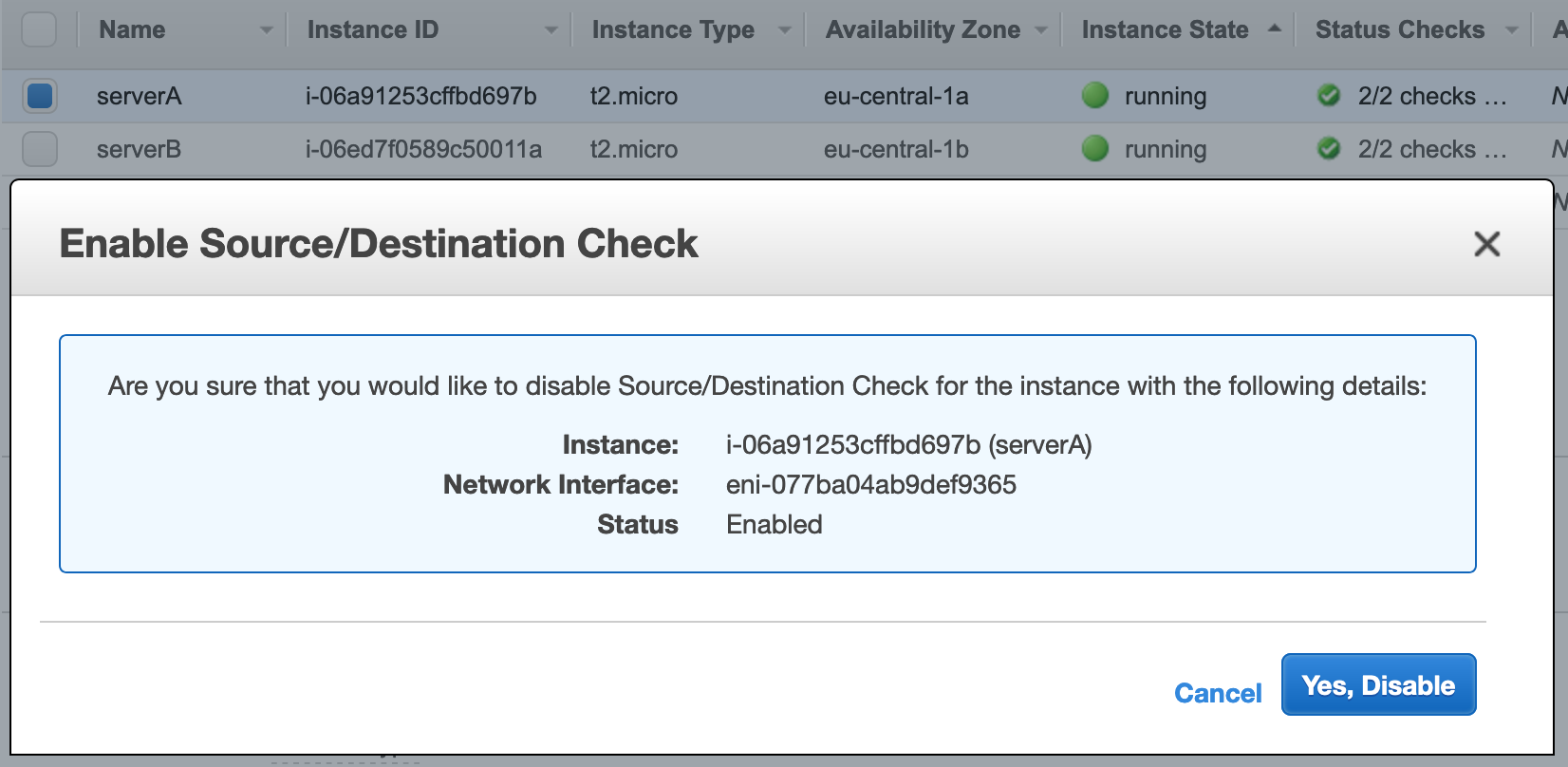
- Disable source/destination checks for the servers to receive traffic for failover IP.
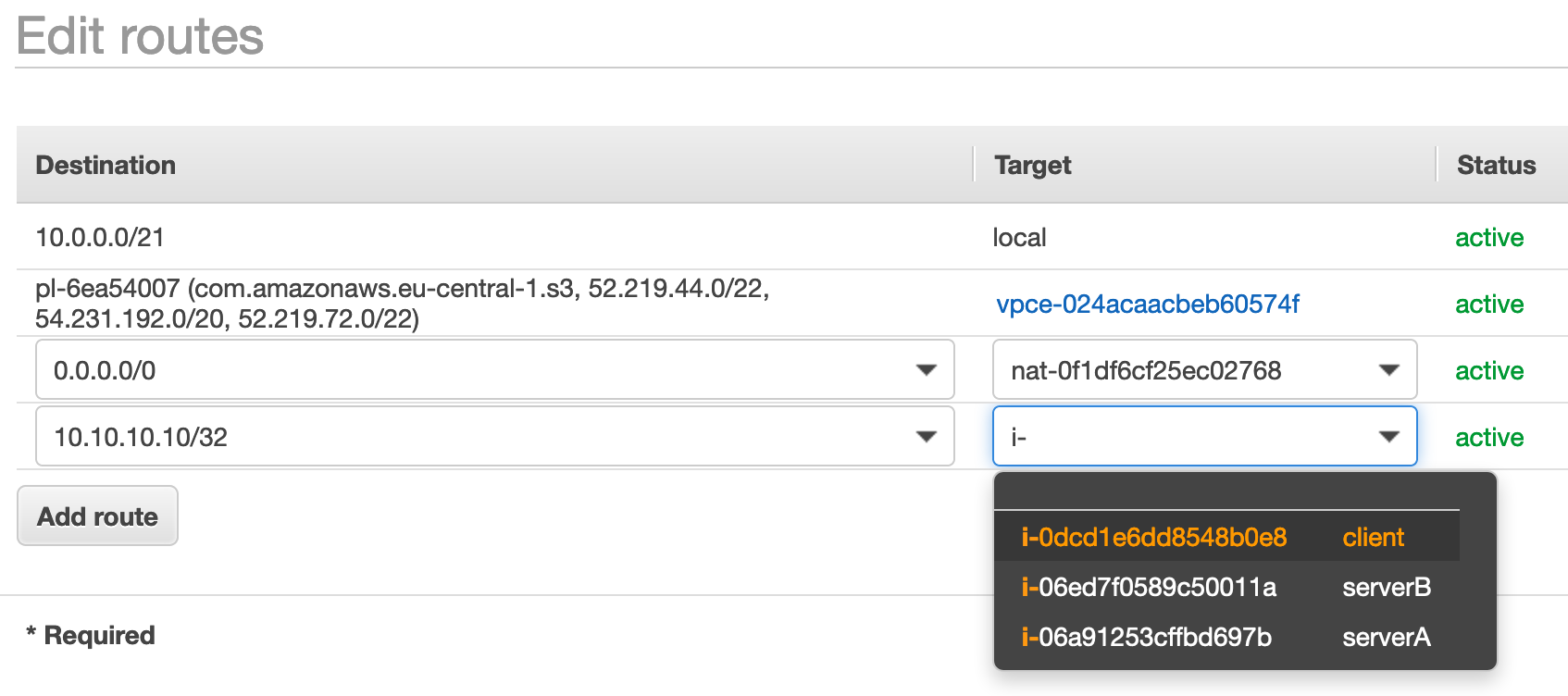
- Modify route table(s) for subnet(s) to route 10.10.10.10 to the serverA.
- DONE!
Now let’s verify from an instance in the same VPC that connection to 10.10.10.10 is routed to serverA. For demonstration I’m using Nginx webserver but this could be any application listening to TCP/UDP traffic on instance.
$ curl -s http://10.10.10.10/ | grep title
<title>Welcome to nginx @serverA!</title>
For IP failover demo, lets start pinging 10.10.10.10 …
$ ping 10.10.10.10
PING 10.10.10.10 (10.10.10.10) 56(84) bytes of data.
64 bytes from 10.10.10.10: icmp_seq=1 ttl=64 time=0.578 ms
64 bytes from 10.10.10.10: icmp_seq=2 ttl=64 time=0.503 ms
...
64 bytes from 10.10.10.10: icmp_seq=19 ttl=64 time=0.431 ms
64 bytes from 10.10.10.10: icmp_seq=20 ttl=64 time=0.570 ms
At this point I edit VPC route table and change 10.10.10.10/32 to serverB.
64 bytes from 10.10.10.10: icmp_seq=21 ttl=64 time=1.04 ms
64 bytes from 10.10.10.10: icmp_seq=22 ttl=64 time=0.981 ms
...
64 bytes from 10.10.10.10: icmp_seq=28 ttl=64 time=0.951 ms
64 bytes from 10.10.10.10: icmp_seq=29 ttl=64 time=0.943 ms
^C
--- 10.10.10.10 ping statistics ---
29 packets transmitted, 29 received, 0% packet loss, time 28443ms
Ping response time increased from 0.5ms to 1.0ms after switching from serverA to serverB. This is because the client and serverA are both in AZ-A but serverB is in AZ-B. To be sure 10.10.10.10 is really routed to serverB lets check I get different response than earlier …
$ curl -s http://10.10.10.10/ | grep title
<title>Welcome to nginx @serverB!</title>
Yes, 10.10.10.10 is now routed to serverB and no ping packets were lost during the failover!
Noteworthy
Above example works only because
-
Both client and servers are within the same VPC. If the client would be outside of VPC, e.g. in on-prem network routing wouldn’t work as VPC would have refused packets addressed outside VPC CIRD (I’d love to be proven wrong)
-
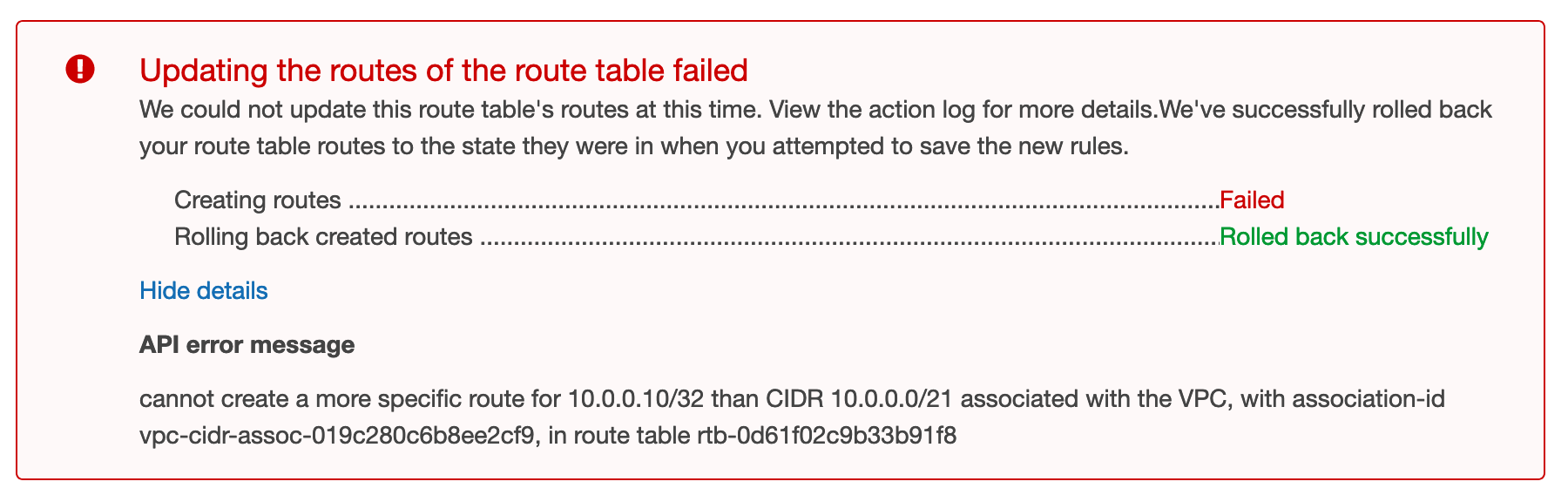
Failover IP is outside of VPC CIDR -range. This may first sound strange but it is requirement for this solution to work. I was hoping the same trick of modifying route tables would also allow routing traffic between partially overlapping VPCs but as it turns out, it is not possible to create a more specific route for network/address inside VPC CIDR than default local -route.
Similar works also in Google Cloud, and I think you can build something similar in Azure too(?)